
التعلم الآلي مباشرة في SQL - كيفية استخدام ML في قواعد البيانات

لا يجب أن يكون التعلم الآلي غامضًا. يتم تغليف الكثير من الأساسيات في حزم برامج عالية المستوى مثل scikit-Learn ، ولكن يمكنك فعل الكثير دون الحاجة إلى مغادرة قاعدة البيانات.
تتيح لك PostgreSQL إنشاء استعلامات تقوم بتشغيل مجموعة متنوعة من خوارزميات التعلم الآلي مقابل بياناتك.
هنا ، أعرض أربع خوارزميات شائعة للتعلم الآلي مكتوبة بالكامل بلغة SQL.
سأقدم هذه الاستعلامات بطريقة تسمح بسهولة العرض ، ولكنها ليست مخصصة للاستخدام في إعداد الإنتاج.
بغض النظر ، يعد العمل من خلالها طريقة رائعة لاختبار معرفتك بكل من التعلم الآلي و SQL ، بالإضافة إلى حل المشكلات - وهي مهارات أساسية لأي عالم بيانات.
الانحدارالخطي
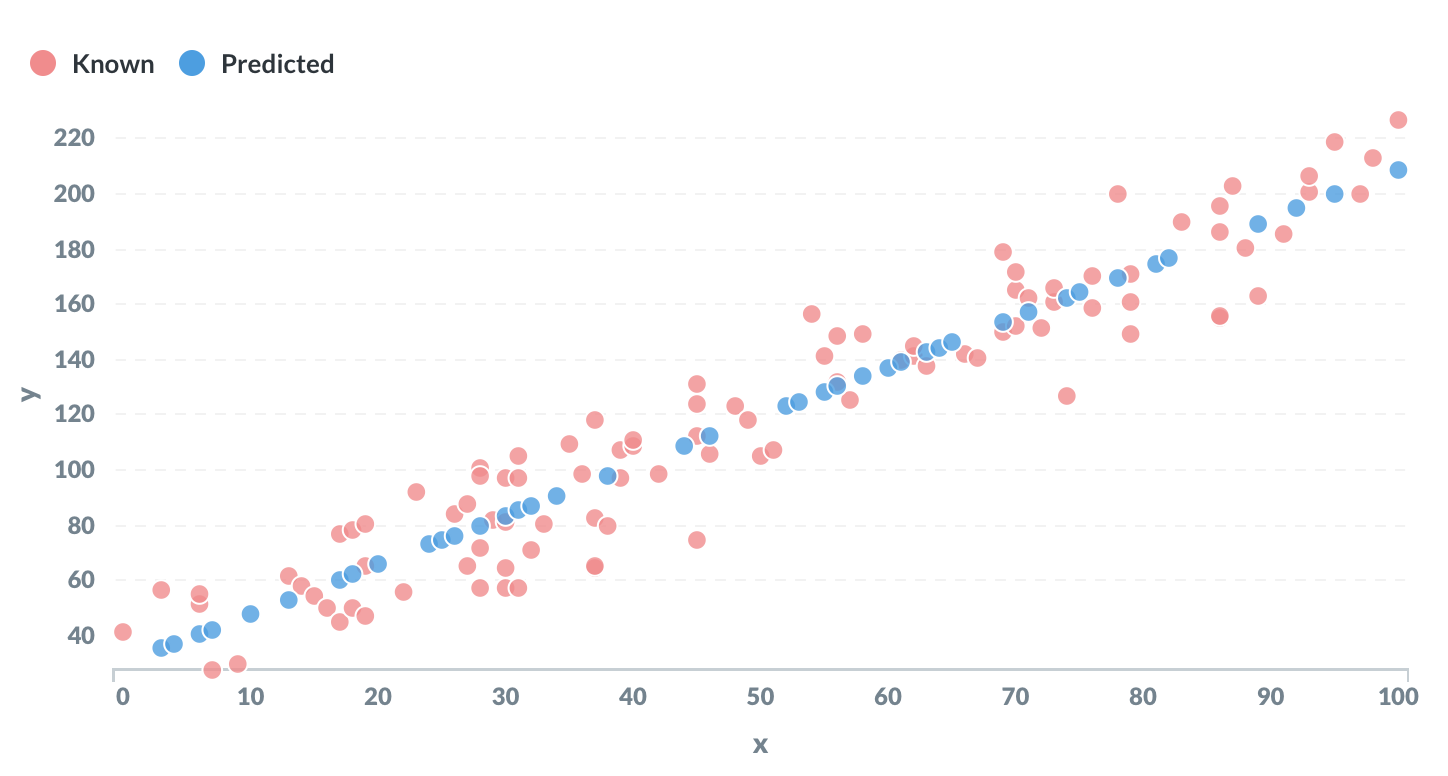
ربما يكون الانحدار الخطي هو المثال الأساسي للتعلم الآلي. الهدف هو "تعلم" المعلمات m و c للمعادلة الخطية بالصيغة y = mx + c من مجموعة من بيانات التدريب.
هذا مثال رائع على الوظائف الإحصائية التي تأتي في ثناياه عوامل مع PostgreSQL.
توجد بيانات الإدخال في جدول مكون من عمودين:
x | ذ
يتم تعيين بعض قيم y على NULL. الهدف هو توقع هذه القيم المفقودة.
WITH regression AS
(SELECT
regr_slope(y, x) AS gradient,
regr_intercept(y, x) AS intercept
FROM
linear_regression
WHERE
y IS NOT NULL
)
SELECT
x,
(x * gradient) + intercept AS prediction
FROM
linear_regression
CROSS JOIN
regression
WHERE
y IS NULL ;تُستخدم الدالتان regr_slope () و regr_intercept () لتقدير التدرج اللوني وشروط التقاطع على التوالي. تتوافق هذه مع المعلمات m و c في المعادلة.
سيكون الناتج جميع النقاط غير المعروفة ، مع قيمة متوقعة لـ y بناءً على قيمة x.
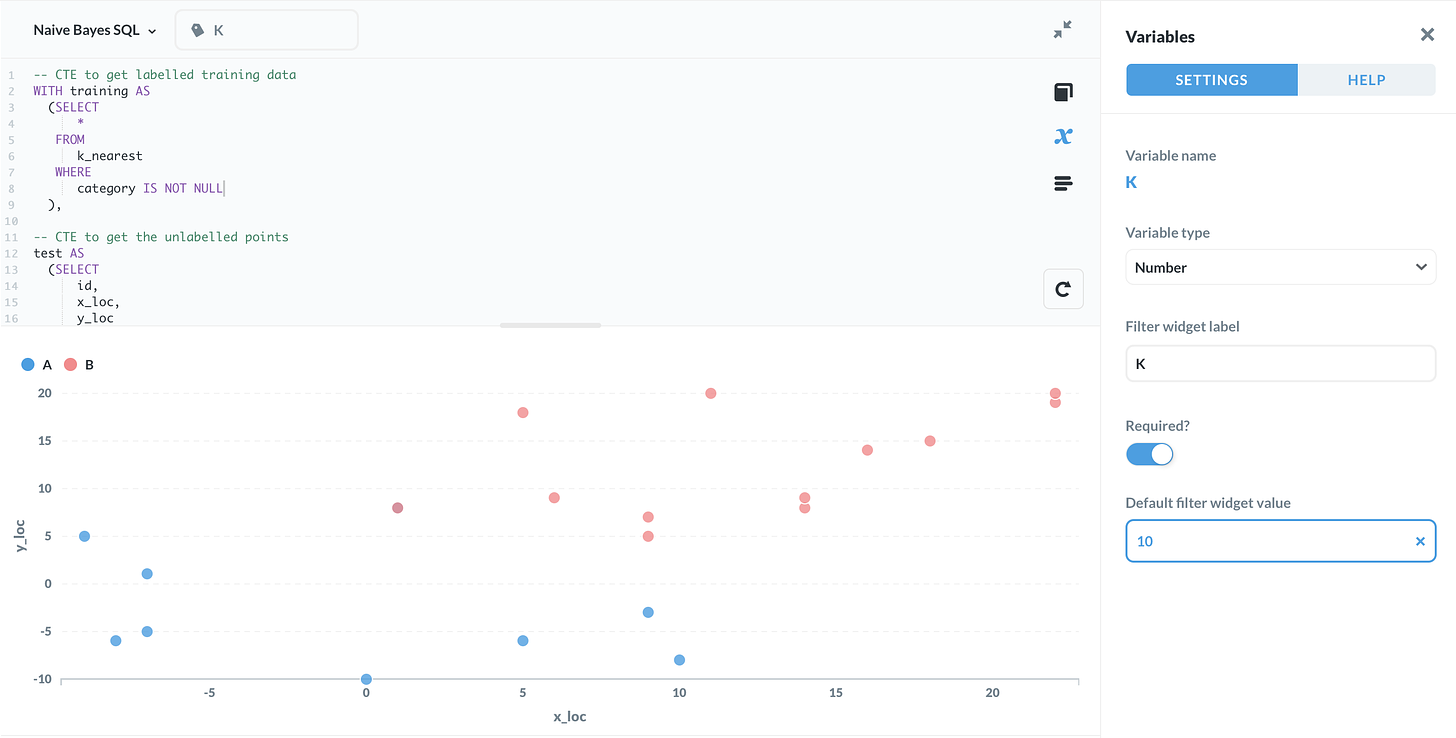
K- أقرب الجيران
K- أقرب جيران هو مثال كلاسيكي على خوارزمية تصنيف خاضعة للإشراف. الفرضية واضحة تمامًا. يتم تمثيل كل نقطة بيانات كنقطة في الفضاء ، معنونة كواحدة من أي عدد من الفئات أو الفئات.
لتصنيف نقطة بيانات غير محددة ، انظر ببساطة إلى تسميات النقاط الأقرب إليها. يتم استخدام الملصق الذي يظهر بشكل متكرر كتقدير.
يتم تحديد عدد النقاط المجاورة التي تم النظر فيها بواسطة المعلمة K.
هنا ، بيانات الإدخال عبارة عن جدول يحتوي على الأعمدة التالية:
معرف | x_loc | y_loc | الفئة
بعض القيم في عمود الفئة هي NULL. الهدف هو تصنيف هذه باستخدام خوارزمية K- الأقرب للجيران.
-- CTE to get labelled training data
WITH training AS
(SELECT
id,
POINT(x_loc, y_loc) as xy,
category
FROM
k_nearest
WHERE
category IS NOT NULL
),
-- CTE to get the unlabelled points
test AS
(SELECT
id,
POINT(x_loc, y_loc) as xy,
category
FROM
k_nearest
WHERE
category IS NULL
),
-- calculate distances between unlabelled & labelled points
distances AS
(SELECT
test.id,
training.category,
test.xy <-> training.xy AS dist,
ROW_NUMBER() OVER (
PARTITION BY test.id
ORDER BY test.xy <-> training.xy
) AS row_no
FROM
test
CROSS JOIN training
ORDER BY 1, 4 ASC
),
-- count the 'votes' per label for each unlabelled point
votes AS
(SELECT
id,
category,
count(*) AS votes
FROM distances
WHERE row_no <= {{K}}
GROUP BY 1,2
ORDER BY 1)
-- query for the label with the most votes
SELECT
v.id,
v.category
FROM
votes v
JOIN
(SELECT
id,
max(votes) AS max_votes
FROM
votes
GROUP BY 1
) mv
ON v.id = mv.id
AND v.votes = mv.max_votes
ORDER BY 1 ASC ;في الاستعلام أعلاه ، تمت كتابة المعامل K كمتغير {{K}}. إذا كنت تستخدم أداة مثل قاعدة التعريف ، فيمكنك إدخال قيم مختلفة لـ K ومعرفة تأثيرها.
يستخدم الاستعلام نوع بيانات PostgreSQL's POINT () وعامل المسافة لحساب المسافات بين البيانات.
ستكون المخرجات عبارة عن كل من النقاط غير المحددة ، جنبًا إلى جنب مع الفئة المقدرة.
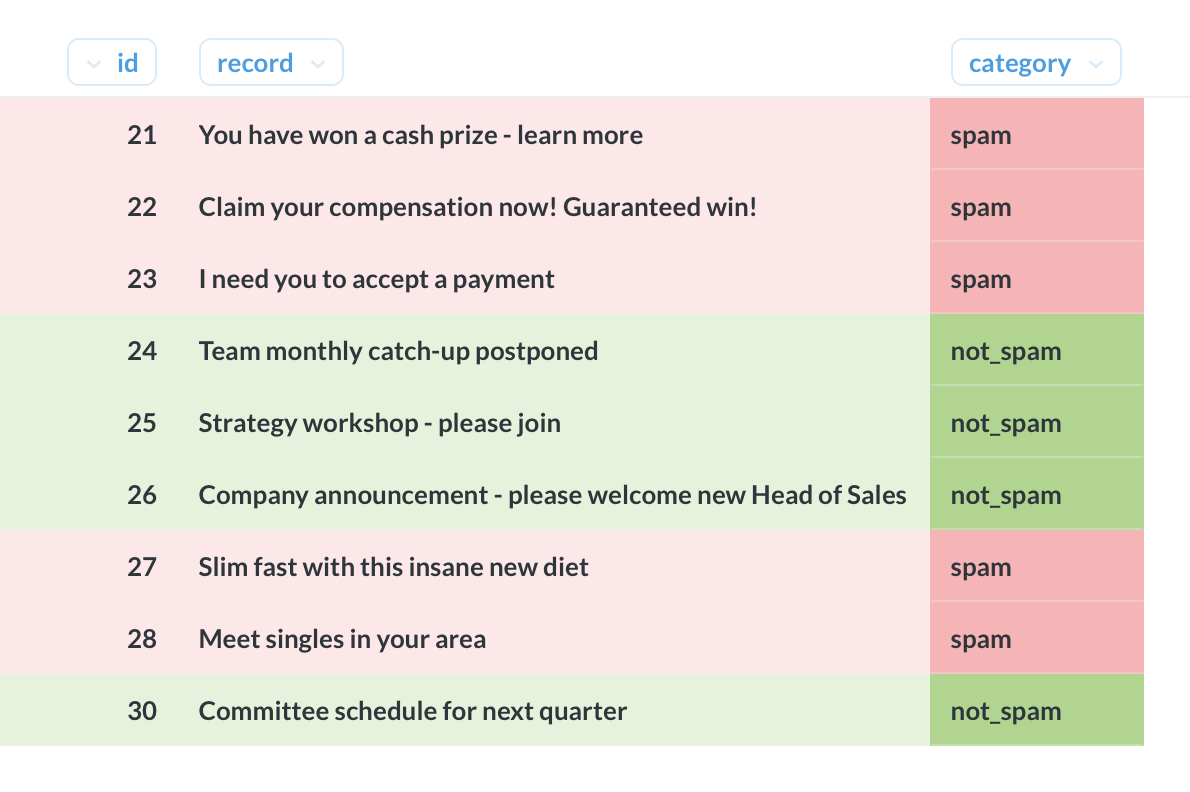
تصنيف بايز ساذج
تصنيف Naive Bayes هو تقنية تستخدم لمهام التصنيف المتنوعة مثل اكتشاف البريد العشوائي من خلال تصنيف المستندات وتحليل المشاعر.
وهو يعمل باستخدام قاعدة بايز لربط "احتمالية الفئة ، بالنظر إلى البيانات" إلى "احتمالية البيانات ، بالنظر إلى الفئة". يمكن تقدير هذا الأخير بسهولة من مجموعة من بيانات التدريب المسمى.
يأخذ الاستعلام أدناه كجدول مع الأعمدة التالية كإدخال:
معرف | سجل | الفئة
هنا ، التسجيل هو جزء من النص (على سبيل المثال ، سطر موضوع البريد الإلكتروني) والفئة هي إحدى الفئات العديدة الممكنة (على سبيل المثال ، البريد العشوائي أو ليس البريد العشوائي).
بالنسبة لبعض الصفوف ، يتم تعيين الفئة على NULL. الهدف هو تقدير الفئات المفقودة باستخدام تصنيف Naive Bayes.
-- CTE to create one row per word
WITH staging AS
(SELECT
REGEXP_SPLIT_TO_TABLE(
LOWER(record), '[^a-z]+') AS word,
category
FROM
naive_bayes
WHERE
category IS NOT NULL
),
-- testing data
test AS
(SELECT
id,
record
FROM
naive_bayes
WHERE
category is NULL
),
-- one row per word + category
cartesian AS
(SELECT
*
FROM
(SELECT
DISTINCT word
FROM
staging) w
CROSS JOIN
(SELECT
DISTINCT category
FROM
staging) c
WHERE
length(word) > 0
),
-- CTE of smoothed frequencies of each word by category
frequencies AS
(SELECT
c.word,
c.category,
-- numerator plus one
(SELECT
count(*)+1
FROM
staging s
WHERE
s.word = c.word
AND
s.category = c.category) /
-- denominator plus two
(SELECT
count(*)+2
FROM
staging s1
WHERE
s1.category = c.category) ::DECIMAL AS freq
FROM
cartesian c
),
-- for each row in testing, get the probabilities
probabilities AS
(SELECT
t.id,
f.category,
SUM(LN(f.freq)) AS probability
FROM
(SELECT
id,
REGEXP_SPLIT_TO_TABLE(
LOWER(record), '[^a-z]+') AS word
FROM
test) t
JOIN
(SELECT
word,
category,
freq
FROM
frequencies) f
ON t.word = f.word
GROUP BY 1, 2
)
-- keep only the highest estimate
SELECT
record,
probabilities.category
FROM
probabilities
JOIN
(SELECT
id,
max(probability) AS max_probability
FROM
probabilities
GROUP BY 1) p
ON probabilities.id = p.id
AND probabilities.probability = p.max_probability
JOIN
test
ON probabilities.id = test.id
ORDER BY 1 ;الإخراج هو كل من السجلات غير المصنفة ، مع تعيين فئة متوقعة.
يقوم الاستعلام أعلاه ببعض التبسيط. أولاً ، المعالجة المسبقة الوحيدة لبيانات النص هي تعبير عادي بسيط للاحتفاظ بالأحرف A-Z ، واستخدام الوظيفة LOWER () لإجبار كل شيء على الأحرف الصغيرة.
كما يفترض أيضًا وجود احتمال مسبق موحد لكل فئة من الفئات (بمعنى آخر ، يكون الافتراض قبل النظر إلى البيانات ، ومن المحتمل أيضًا أن تكون رسائل البريد الإلكتروني العشوائية وغير العشوائية متساوية)
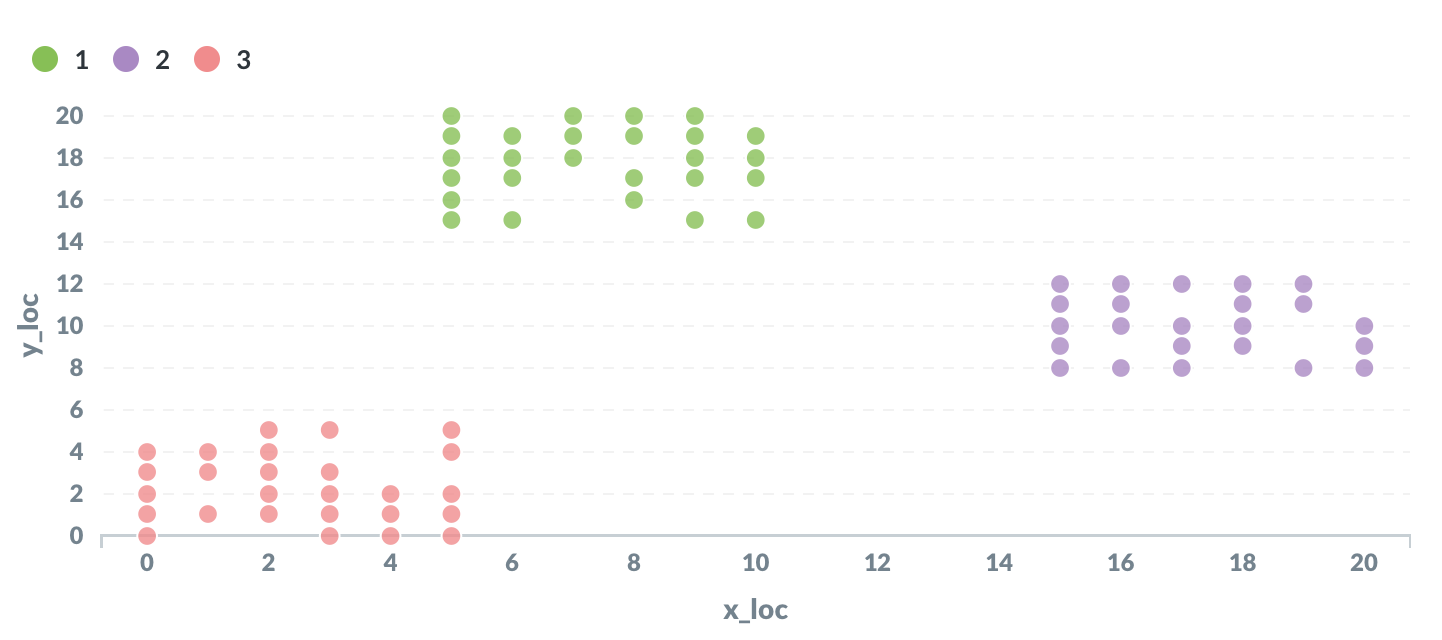
K- يعني التجميع
K-mean clustering هو خوارزمية تصنيف معروفة. إنها خوارزمية غير خاضعة للإشراف ، مما يعني أنها لا تتطلب أي بيانات تدريب مصنفة.
يعمل التجميع K- عن طريق تمثيل كل نقطة بيانات كنقطة في الفضاء. يتم تعيين كل نقطة مبدئيًا بشكل عشوائي لإحدى مجموعات K (حيث K هي معلمة يتم اختيارها مسبقًا).
بعد ذلك ، يتم حساب متوسط موقع النقاط لكل مجموعة.
بعد ذلك ، يتم إعادة تعيين كل نقطة إلى المجموعة ذات أقرب موقع متوسط.
تتكرر هاتان الخطوتان مرارًا وتكرارًا حتى لا يتم إعادة تعيين النقاط بين الخطوات.
بيانات الإدخال عبارة عن جدول يحتوي على الأعمدة التالية:
معرف | x_loc | y_loc
الإخراج هو المجموعة الكاملة من النقاط ، كل منها مخصص لواحدة من مجموعات K.
كان هذا صعب التنفيذ. يعتمد الحل أدناه بشكل كبير على تعميم مثال بيانات الشراء هذا الذي تم إنشاؤه بواسطة Jim Nasby بموجب ترخيص BSD 2-clause (والذي ينطبق أدناه).
WITH points AS
(SELECT
id,
POINT(x_loc, y_loc) AS xy
FROM
k_means_clustering
),
initial AS
(SELECT
RANK() OVER (
ORDER BY random()
) AS cluster,
xy
FROM points
LIMIT {{K}}
),
iteration AS
(WITH RECURSIVE kmeans(iter, id, cluster, avg_point) AS (
SELECT
1,
NULL::INTEGER,
*
FROM
initial
UNION ALL
SELECT
iter + 1,
id,
cluster,
midpoint
FROM (
SELECT DISTINCT ON(iter, id)
*
FROM (
SELECT
iter,
cluster,
p.id,
p.xy <-> k.avg_point AS distance,
@@ LSEG(p.xy, k.avg_point) AS midpoint,
p.xy,
k.avg_point
FROM points p
CROSS JOIN kmeans k
) d
ORDER BY 1, 3, 4
) r
WHERE iter < {{max_iter}}
)
SELECT
*
FROM
kmeans
)
SELECT
k.*,
cluster
FROM
iteration i
JOIN
k_means_clustering k
USING(id)
WHERE
iter = {{max_iter}}
ORDER BY 4,1 ASC ;يستخدم هذا الاستعلام ميزتين أنيقتين.
أولاً ، تستخدم أنواع البيانات الهندسية ومشغليها في PostgreSQL لنمذجة البيانات من حيث النقاط وأجزاء الخط.
كما أنه يستخدم استعلامًا تعاوديًا لإعادة حساب مراكز كل مجموعة بشكل متكرر حتى أقصى عدد من التكرارات.
يستخدم هذا التطبيق عددًا محددًا مسبقًا من التكرارات قبل الإنهاء ، بدلاً من التوقف بمجرد توقف إعادة تعيين النقاط بين التكرارات.
إذا كنت تستخدم أداة مثل قاعدة التعريف ، فيمكنك تعيين المعلمات K والحد الأقصى لعدد التكرارات ديناميكيًا باستخدام المتغيرين {{K}} و {{max_iter}}.
جميل جدا
ردحذف